No post Primeiros passos para análise de dados com Python demos uma breve justificativa do porquê utilizar o Python para fazer análise de dados. Na série de posts que começamos hoje, vamos realizar todas as etapas de análise de uma base de dados, para responder a duas perguntas específicas.
Na especialização em Data Science oferecida pelo site do Coursera, pela Johns Hopkins University, foi disponibilizada no quinto módulo - Reproducible Research - uma base de dados da U.S. National Oceanic and Atmospheric Administration's (NOAA) com as características e dados sobre as principais tempestades e eventos climáticos nos Estados Unidos. Esta base inclui informações da data de ocorrência, da localidade, quantidade de fatalidade e danos a indivíduos e propriedades. A base está disponível em https://d396qusza40orc.cloudfront.net/repdata%2Fdata%2FStormData.csv.bz2 e também temos a documentação no National Weather Service. O arquivo está compactado no formato bz2.
Como desafio do projeto, vamos responder à duas perguntas:
1 - Quais são os eventos climáticos (atributo EVTYPE) mais danos à população?
2 - Quais os tipos de eventos climáticos que mais causam danos econômicos?
Já finalizamos o código em R, disponível em
e agora vamos trabalhar em Python para chegar ao mesmo resultado. A análise em Python será baseada na biblioteca pandas, muito popular para análise de dados.
Mais do que apenas uma biblioteca, pandas é um pacote que prove velocidade, flexibilidade e robustas estruturas de dados, projetadas para facilitar o trabalho com informações relacionais. Os mais apaixonados diriam que é o pacote open source mais flexível e poderoso já disponibilizado em qualquer linguagem. Exageros à parte, de fato é um módulo muito útil para trabalharmos com data frames em aplicações de finanças, estatística e diversas áreas da engenharia. Possui sintaxe muito semelhante ao DataFrame do R, com a diferença que o pandas é fortemente integrado com o módulo NumPy. Esta característica o faz o pacote preferido para aplicações em finanças pois também possuem excelentes módulos integrados para análise de séries temporais. Outra vantagem é a possibilidade de trabalharmos com leitura e escrita em diversos formatos, como CSV e TXT, além de XLS, bases em SQL e o formato HDF5.
Após esta breve introdução, vamos à prática. Começamos com o seguinte código:
import pandas as pd
import io
import urllib2
import bz2
#Abrindo a URL e descompactando o arquivo .bz2
url = "https://d396qusza40orc.cloudfront.net/repdata%2Fdata%2FStormData.csv.bz2"
raw_bz2 = urllib2.urlopen(url).read()
data = bz2.decompress(raw_bz2)
df = pd.read_csv(io.BytesIO(data))
df.head()
subSet = df[['BGN_DATE','PROPDMG','CROPDMG','EVTYPE','INJURIES','FATALITIES']]
No primeiro bloco importamos as bibliotecas que serão utilizadas, com destaque para a bz2 que utilizamos para descompactar o arquivo e o pandas, para nossa análise de dados. Na sequência, fazemos o download da base com a urllib2 e utilizamos o método bz2.decompress para abrir o arquivo. Como ele está em .cvs, utilizados o método read_csv do pandas para carregar a base em um dataframe. O comando head() sumariza nossa base, como mostrado abaixo:

Uma das facilidades de trabalhar com dataframe é a facilidade de criarmos subconjuntos dos dados. Não vamos trabalhar com todas as 37 colunas de nossa base, mas apenas com os atributos 'BGN_DATE','PROPDMG','CROPDMG','EVTYPE','INJURIES','FATALITIES'. Logo para selecioná-las basta que elas sejam parâmetros de sua seleção.
Operações fundamentais
Antes de prosseguirmos com esta análise, vamos entender as operações fundamentais do pandas no Python. Podemos listar como sendo 5 as operações elementares: criar, carregar, preparar, analisar e apresentar os dados. Já vimos como carregar dados em cvs (read_csv()). Vamos nos atentar as outras 4 operações.
Criação e preparação dos dados
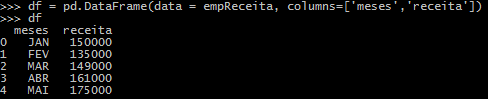
Suponha que tenhamos duas listas como abaixo:
receita = [150000,135000,149000,161000,175000]
meses = ['JAN','FEV','MAR','ABR','MAI']
Podemos concatenar estas informações com o método zip():

Com isto preparamos os dados para inseri-los no DataFrame:
Análise básica
Podemos ordenar os dados para saber qual foi o mês com maior receita na empresa:

Saber qual foi o mês associado ao menor valor de receita:

Apresentação dos dados
Outra facilidade é o modo como podemos gerar um gráfico. Vamos visualizar as receitas da empresa no tempo, adicionando uma legenda:


Esta são as operações mais básicas e de baixa complexidade. Entretanto, é importante termos os conceitos fundamentais bem sólidos, para que possamos incrementar a dificuldade em nossa análise. O código dataAnalysis.py com esta primeira etapa de análise da base Storm_Database está disponível no Github e será atualizado conforme avançarmos nos posts.
Um abraço e até o próximo!
0 comentários:
Postar um comentário