No post anterior
estudamos como comparar strings com uma métrica baseada na Distância de Levenshtein, que é a medida que calcula a diferença entre duas sequências, baseada no número de caracteres mínimos que devem ser mudados para transformar uma sequência em outra. No post de hoje, vamos falar sobre a Distância de Jaccard.
Não apenas entre strings mas as vezes temos interesse em calcular a similaridade e a diversidade em um conjunto de coisas, definindo conjunto como uma coleção não ordenada de items. É neste tipo de aplicação que utilizamos a distância de Jaccard (dJ), calculada pela relação da intersecção com a união de dois conjuntos.
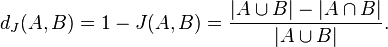
ou seja, o número de items únicos em comum aos dois conjuntos dividido pelo número total de items distintos, subtraídos de 1. Sendo mais preciso, a distância de Jaccard mensura a dissimilaridade entre dois conjuntos, enquanto o coeficiente de Jaccard mede a similaridade, e é dado por
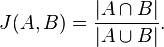
Por esta definição, entendemos o porque desta métrica calcular a similaridade e a diversidade entre dois conjuntos.
Na prática, podemos utilizar o coeficiente de Jaccard para, por exemplo, calcular a similaridade entre dois temas, baseados em suas palavras-chave. No site http://academic.research.microsoft.com/ podemos realizar uma pesquisa de quais são as palavras chaves utilizadas em publicações sobre um determinado tema. No código keywordSimilarity.py avaliamos a similaridade, pelo coeficiente de Jaccard, das 100 palavras-chaves mais frequentes relacionadas à Machine Learning e Artificial Intelligence.
Como resultado do algoritmo, temos

Ou seja, o coeficiente mostra que temos baixa similaridade entre as palavras-chave dos dois temas, que as vezes são confundidos no dia-a-dia.
Um abraço e até o próximo post!
0 comentários:
Postar um comentário