Olá!
Nos últimos 2 posts
introduzimos um novo conceito de programação com Python e iniciamos uma análise de dados completa. No post de hoje, damos continuidade a este estudo mostrando mais sobre a biblioteca pandas e a manipulação de dataframes. Utilizando a ferramenta IPython Notebook, estruturamos nossa análise como um relatório para publicação. Vamos ao passo a passo.
O IPython suporta a linguagem markdown - Markdown é uma linguagem simples de marcação originalmente criada por John Gruber. Ele marca alterações nos textos (subtítulos, negrito, itálico etc) apenas com os símbolos do teclado. Abaixo, alguns exemplos de sintaxe :
Heading ======= Sub-heading ----------- h3. Traditional html title Paragraphs are separated by a blank line. Let 2 spaces at the end of a line to do a line break Text attributes *italic*, **bold**, `monospace`.
E o respectivo resultado:
Heading
Paragraphs are separated by a blank line.
Let 2 spaces at the end of a line to do a
line break
line break
Text attributes italic, bold,
monospace.
Começamos nosso relatório com um markdown mostrando título, autor e um breve resumo da análise.

Agora, repetimos o início da análise mostrado no post anterior

Agora, a partir da linha 4, selecionamos apenas alguns atributos que utilizaremos na análise. Selecionamos as respectivas colunas e criamos um novo dataframe (df) chamado subSet. O comando subSet.head() da linha 7 mostra as primeiras linhas deste novo dataframe.

Vamos inserir uma nova variável, que é a soma de PROPDMG e CROPDMG.

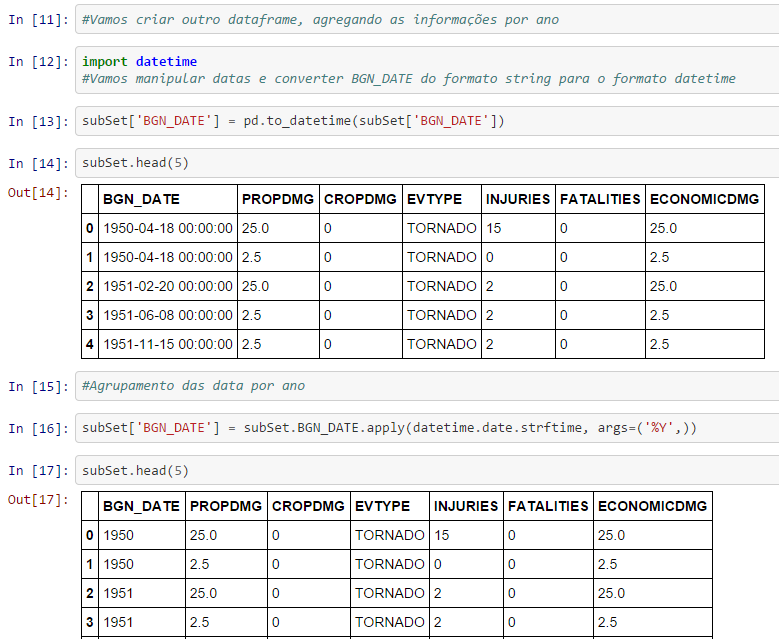
Repare nas visualizações anteriores que a granularidade do campo BGN_DATE (data do evento) é diária. Para facilitar a análise, vamos agrupar as informações por ano, como mostrado a seguir. Utilizamos o método to_datetime para fazer a padronização das datas. Na sequência, utilizamos o método datetime.date.strftime, args=('%Y',) da biblioteca datetime para obter apenas a informação do ano (args=('%Y',)).
Agora, importamos a biblioteca numpy para os cálculos de média, soma e desvio padrão. Antes disso, agrupamos os dados por ano e tipo de evento com o método .groupby(['BGN_DATE','EVTYPE']) para então utilizar o agg() e chamar np.mean, np.std e np.sum.

Nas linhas 22, 23 e 24, agregamos os novos dados à variável eventYear e fazemos a concatenação de cada atributo. Renomeamos a coluna 'sum' para o respectivo nome da ocorrência.

Por fim, temos os dados agregados por ano e tipo de evento, associados a cada ocorrência.

Para não termos um post muito extenso, deixaremos para a parte 3 a visualização das informações e a conclusão da análise. Acesse nosso Github ou visite o link abaixo para o código completo.
Um abraço e até o próximo post!
0 comentários:
Postar um comentário